

Over the last few years, new open-source AI models have commoditized capabilities initially only accessible to a few. In the mid-2010s this happened with general object recognition algorithms. In late 2022, it happened again with models like Stable Diffusion for image generation and then Whisper for audio transcription (the focus of this post!). It doesn’t take a leap of faith to realize that this sort of thing is going to keep happening. More and more magical capabilities will continue to be released completely open-source.
Historically, audio transcription has been a niche use case only a few companies enabled as an API — namely products like Deepgram, AssemblyAI, RevAI, and the major cloud providers like AWS, GCP, and Azure. These services are all amazing for their own reasons but it always tends to be a tradeoff between quality, cost, and speed. Most blog posts also tend to bore you with the exact tradeoffs but I’m going to leave you with some questions.
What would you build if you had access to dirt cheap audio transcription that actually worked?
What if you could make the cost, quality, and accuracy tradeoff yourself?
What if it was full-featured with capabilities covering higher level intelligence on top of the data, diarization, live support, etc?
At Sieve, we are launching just this. You can try it out here for yourself.

As a part of this app, we’re also letting you choose between options that let you make the tradeoffs on speed, quality, and cost yourself. Below we compare with other transcription providers.
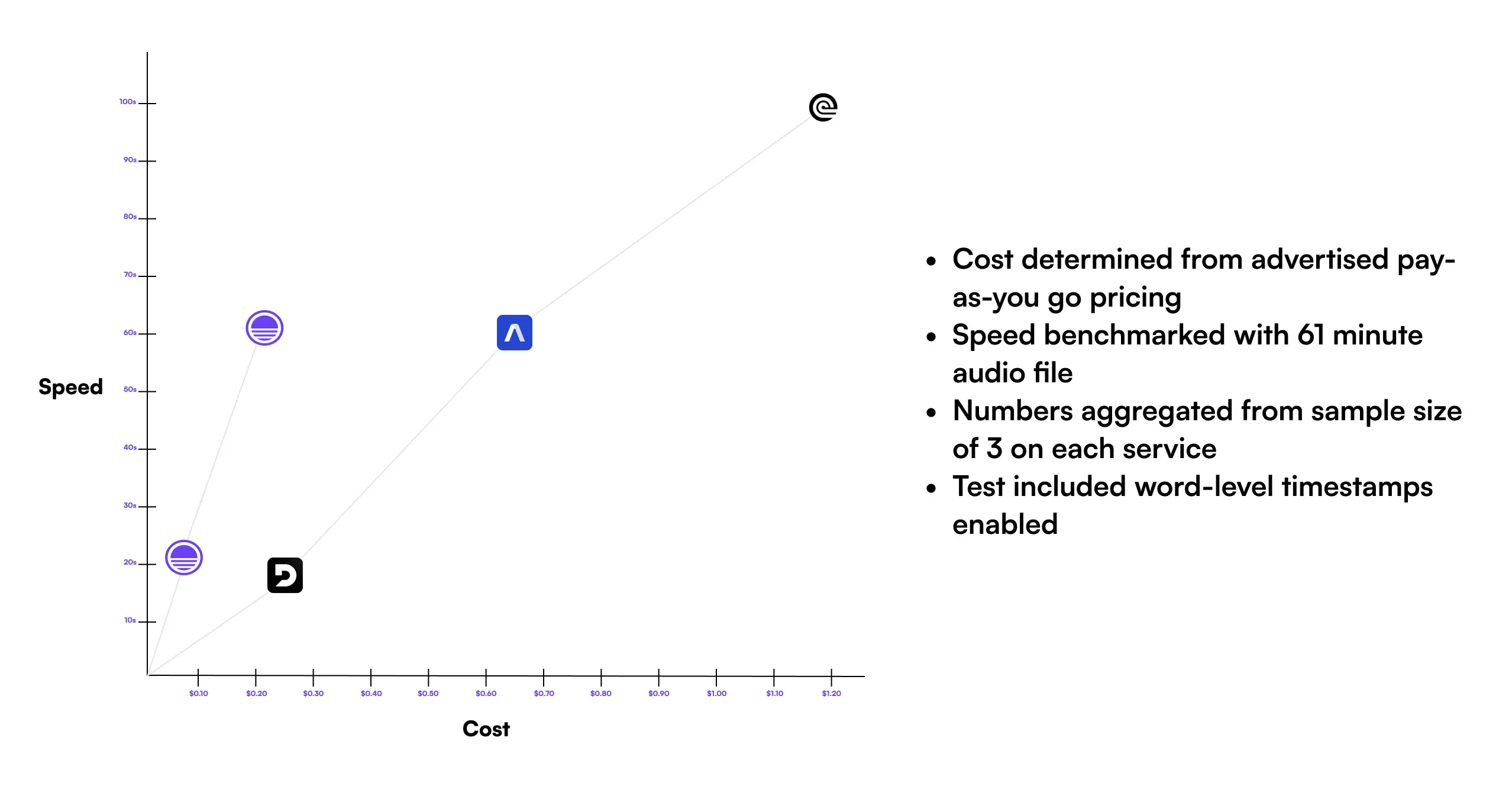
| Solution | Cost | Speed |
|---|---|---|
| Sieve (speed_boost) | $0.05 / hr | 21s |
| Sieve (decode_boost) | $0.179 / hr | 62s |
| Deepgram (Nova 2) | $0.258 / hr | 19s |
| AssemblyAI | $0.65 / hr | 60s |
| RevAI | $1.20 / hr | 99s |
How???
Under the hood, we’re using various optimized, highly accurate versions of the Whisper model. As a baseline, Whisper is great but it doesn’t offer functionality like word-level timestamps, diarization, fast processing speeds, streamed outputs, etc out of the box — most of which tend to be requirements for many applications.
Projects like faster-whisper helped push on speed of the model by reimplementing it with CTranslate2. Other projects like WhisperX used this backend and offered things like diarization and word-level timestamps on top of it, but with limitations on multi-lingual capabilities. At Sieve, we took some of this amazing work and pushed it further.
On Speed
While running OpenAI’s Whisper implementation on its own can be 7-8x slower than other transcription providers, we’ve made significant improvements here to make it close to the fastest solution on the market. One interesting thing you can do to speed up processing of audio data in transcription is by splitting it up into chunks by detecting silences, and then parallelly running it through models like Whisper. However, this only works if you have an easy way to distribute work on many GPU machines and the ability to handle bursty workloads on your infrastructure (which tends to be hard when these Docker images take 6+ minutes to even load onto a Kubernetes cluster). On Sieve, we’ve solved some of these problems and have a parallel chunking approach implemented that also leverages your ability to use public functions (which are also used by other Sieve users) to get highly available, highly parallel processing done. Check out the implementation here.
On Accuracy
Many articles about speech-to-text highlight WER as a key metric for evaluating speech recognition, but the reality is more nuanced. While metrics like WER offer a numerical value for comparison — with some AI sales products boasting about a low WER — they often fail to capture the full picture of an ASR system's effectiveness. For instance, a 14.75% WER might seem impressive, but what does it really tell us about the system’s performance in practical scenarios? Engineers on platforms such as Hacker News have critiqued WER as being somewhat of a red herring, a metric more useful for marketing than for meaningful evaluation.

The core issue with WER is its lack of context and semantic sensitivity. It simply counts word errors without considering their impact on the overall message or context in which they occur. For example, misrecognizing a key word in a critical business meeting can change the meaning entirely, despite having a 'low' WER.

In essence, WER can be a superficial measure, not fully indicative of an ASR system's utility in real-world applications. What matters more is how well the ASR system addresses specific use cases, especially when integrated with the surrounding systems that are then presented to the end-users. This is where Sieve's enhancements to the Whisper model shine. By focusing on practical aspects such as word level timestamps and employing techniques like Dynamic Time Warping (DTW) on cross-attention weights, Sieve significantly improves the utility of ASR in diverse applications — something that a traditional metric like WER might not fully encapsulate. We’ve specifically found Sieve’s improvements over the vanilla Whisper model to perform well in use cases including but not limited to:
- Video Meetings
- Phone Calls
- Podcasts / Webshows
- Scripted media content like TV and movies
On Cost and Broader Offerings
The cheapest option on Sieve is 5x cheaper than the next cheapest provider for transcription. The reason we can do this is because Sieve is not just a transcription provider. We have a much broader offering focused on serving all sorts of video and audio AI use cases. While customers tend to come to us with a single feature in mind, most of them start using Sieve’s other out-of-the-box apps covering many use cases you can explore here or even deploying their own custom applications onto Sieve as well. Why work with 10 different API providers, if you can build all your functionality with just one?
With transcription becoming more of a commodity, we see this as the right thing to do. We’ve optimized the hell out of our GPU infrastructure to enable this. We think this will continue to enable more use cases in media, call centers, conversational AI, and more.
Sieve’s platform offering around many use cases and modular building blocks also makes it really easy for Sieve to bake in complex functionality into our transcription offering including:
- speaker diarization
- live stream support
- translation
- summarization
- auto-chapters
- auto-titles
- auto-tags
- sentiment analysis
- contextual queues
These are all available on the pre-recorded offering and live offering. You can also check our transcript analysis app which strings the audio intelligence features on top.
Conclusion
At Sieve, we’re continuing to push on what can be done with the ever changing AI landscape to make it easier to build all sorts of AI applications. We also often work with teams on use cases where they require a more custom tradeoff between speed, accuracy, and other intelligent functionality built on top. If you’d like to speak with team on your specific use-case or you’re curious of more technical details, feel free to book a demo with us today.